사이버 보안 회사인 CrowdStrike가 배포한 잘못된 업데이트로 인해 전 세계 기업들이 Windows 워크스테이션에 광범위한 중단을 겪었습니다.
“CrowdStrike은 Windows 호스트의 단일 콘텐츠 업데이트에서 발견된 결함으로 인해 영향을 받은 고객과 적극적으로 협력하고 있습니다.” 회사의 CEO인 조지 커츠가 성명에서 밝혔습니다. “Mac 및 Linux 호스트는 영향을 받지 않습니다. 이는 보안 사고나 사이버 공격이 아닙니다.”
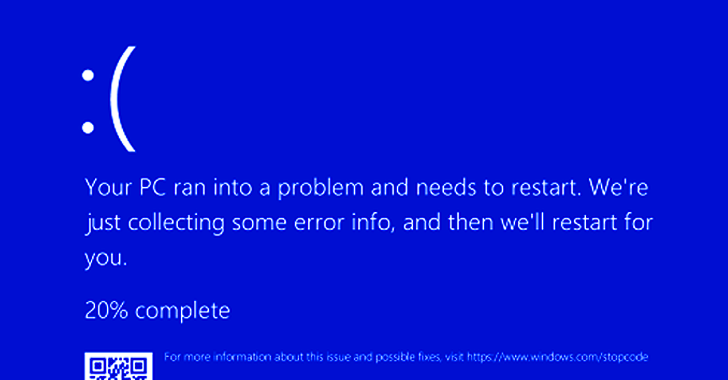
“윈도우 호스트에서 (죽음의 블루 스크린)이 보고되었다”는 사실을 인정한 이 회사는 또한 이 문제를 확인했으며 Falcon Sensor 제품에 대한 수정판을 배포했으며, 고객들에게 최신 업데이트를 받으려면 지원 포털을 참조하라고 촉구했습니다.
이미 문제의 영향을 받은 시스템의 경우 완화 지침은 아래와 같습니다.
- 안전 모드 또는 Windows 복구 환경에서 Windows 부팅
- C:WindowsSystem32driversCrowdStrike 디렉토리로 이동합니다.
- “C-00000291*.sys”라는 파일을 찾아 삭제하세요.
- 컴퓨터 또는 서버를 정상적으로 다시 시작합니다.
주목할 점은 이번 서비스 중단으로 인해 Google Cloud Compute Engine에도 영향이 미쳐 CrowdStrike의 csagent.sys를 사용하는 Windows 가상 머신이 충돌하고 예기치 않은 재부팅 상태에 빠졌다는 것입니다.
“CrowdStrike에서 결함이 있는 패치를 자동으로 받은 후 Windows VM이 충돌하고 재부팅할 수 없게 됩니다.”라고 말했습니다. “현재 작동 중인 Windows VM은 더 이상 영향을 받지 않습니다.”
Microsoft Azure도 비슷한 업데이트를 게시하면서 “영향을 받은 가상 머신에서 여러 가상 머신 재시작 작업을 시도한 일부 고객으로부터 성공적인 복구 보고를 받았습니다”라고 말하며 “여러 번의 재부팅(최대 15회 보고됨)이 필요할 수 있습니다.”라고 덧붙였습니다.
Amazon Web Services(AWS)는 가능한 한 많은 Windows 인스턴스, Windows Workspace 및 Appstream 애플리케이션에 대해 문제를 완화하기 위한 조치를 취했으며, 여전히 문제의 영향을 받는 고객에게 “연결을 복원하기 위한 조치를 취하라”고 권고했습니다.
보안 연구원 케빈 보몬트는 “자동 업데이트를 통해 그들이 푸시한 CrowdStrike 드라이버를 얻었습니다. 어떻게 된 일인지는 모르겠지만, 파일이 올바르게 포맷된 드라이버가 아니어서 Windows가 매번 충돌합니다.”라고 말했습니다.
“CrowdStrike는 최상위 EDR 제품이며 POS부터 ATM 등 모든 것에 적용됩니다. 이는 영향 면에서 전 세계적으로 가장 큰 ‘사이버’ 사고가 될 가능성이 큽니다.”
항공사, 금융 기관, 식품 및 소매 체인점, 병원, 호텔, 뉴스 기관, 철도망, 통신 회사 등이 영향을 받은 많은 기업 중 일부입니다. CrowdStrike의 주가는 미국 장전 거래에서 15% 폭락했습니다.
CyberArk의 최고정보책임자(CIO) 오머 그로스만은 The Hacker News와 공유한 성명에서 “현재의 사건은 7월에도 2024년 가장 중요한 사이버 문제 중 하나가 될 것으로 보인다”고 말했습니다. “글로벌 수준에서 비즈니스 프로세스에 대한 피해는 엄청납니다. 이 결함은 CrowdStrike의 EDR 제품 소프트웨어 업데이트로 인한 것입니다.”
“이 제품은 엔드포인트를 보호하는 높은 권한으로 실행되는 제품입니다. 이 제품의 오작동은 현재 사건에서 보듯이 운영 체제가 충돌할 수 있습니다.”
Grossman은 문제를 수동으로, 엔드포인트별로 해결해야 하므로 복구에 며칠이 걸릴 것으로 예상하고 안전 모드에서 시작하여 버그가 있는 드라이버를 제거해야 한다고 지적하면서, 오작동의 근본 원인을 찾는 것이 “최대한 중요할 것”이라고 덧붙였습니다.
슬로바키아 사이버 보안 회사 ESET의 글로벌 보안 고문인 제이크 무어는 The Hacker News에 이 사건이 여러 가지 “안전 장치”를 구현하고 IT 인프라를 다양화해야 할 필요성을 강조하는 역할을 한다고 말했습니다.
Moore는 “시스템과 네트워크의 업그레이드와 유지관리에는 의도치 않게 작은 오류가 포함될 수 있으며, 이는 오늘날 CrowdStrike의 고객이 경험한 것처럼 광범위한 결과를 초래할 수 있습니다.”라고 말했습니다.
“이 사건의 또 다른 측면은 대규모 IT 인프라 사용의 ‘다양성’과 관련이 있습니다. 이는 운영 체제(OS), 사이버 보안 제품 및 기타 전 세계적으로 배포된(확장된) 애플리케이션과 같은 중요한 시스템에 적용됩니다. 다양성이 낮은 경우 단일 기술 사건은 물론 보안 문제도 글로벌 규모의 중단으로 이어져 후속적인 영향을 미칠 수 있습니다.”
Microsoft는 Defender, Intune, OneNote, OneDrive for Business, SharePoint Online, Windows 365, Viva Engage, Purview 등 Microsoft 365 앱과 서비스에 문제를 일으킨 별도의 중단에서 복구하는 과정에서 이러한 개발이 이루어졌습니다.
“Azure 백엔드 워크로드 일부의 구성 변경으로 인해 스토리지와 컴퓨팅 리소스 간에 중단이 발생하여 이러한 연결에 의존하는 다운스트림 Microsoft 365 서비스에 영향을 미치는 연결 장애가 발생했습니다.”라고 기술 거대 기업이 밝혔습니다.
OpenSSF의 총괄 매니저인 옴카르 아라사라트남은 Microsoft-CrowdStrike 중단 사고는 단일 문화 공급망의 취약성을 강조하고 더 큰 회복력과 보안을 위해 기술 스택의 다양성이 중요함을 강조했다.
“단일 문화적 공급망(단일 운영 체제, 단일 EDR)은 본질적으로 취약하고 체계적 결함에 취약합니다. 우리가 보았듯이요.” Arasaratnam이 지적했습니다. “좋은 시스템 엔지니어링은 이러한 시스템의 변경 사항이 점진적으로 전개되어야 하며, 한꺼번에 모든 것을 관찰하는 것보다 작은 단위로 영향을 관찰해야 한다는 것을 알려줍니다. 더 다양한 생태계는 체계적 문제에 회복력이 있기 때문에 빠른 변화를 견딜 수 있습니다.”







